Scaling parallel IO in ASPECT
The goal of this post is to evaluate the performance of generating visualization output for large computations produced by ASPECT. ASPECT uses deal.II to generate the visualization output. By default we generate VTU files of the unstructured mesh. Instead of generating one file per MPI rank, the output can be grouped to a specified number of files (even a single one). These files are written using MPI I/O, which should allow for fast performance.
Machine setup and striping
- Computations done on Frontera, nsinker benchmark, adaptive refinement
- Computations were done on 32 nodes (56 cores each)
- /scratch1/ LFS filesystem has 16 OSTs (file servers), up to 60 GB/s
- Striping can be enabled (-1 = maximum striping) by calling
lfs setstripe -c -1 <file or fikder> - default striping is 1 (disabled)
Results
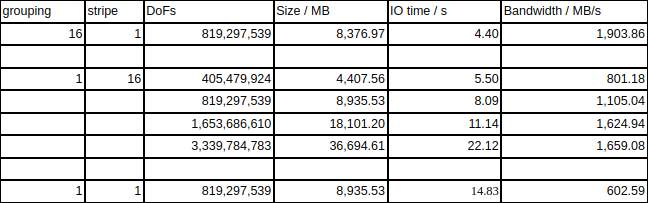
Conclusions
This little experiment showed some interesting results:
-
For now, grouping to 16 without striping gives the best performance. This is the default in ASPECT.
-
We can achieve up to 2 GB/s in performance. This is far from the theoretical maximum.
-
Overall, performance is good enough: The linear solver takes about 30 seconds for 800m DoFs (IO: 5 seconds).
Future work
-
Compare against HDF5 output.
-
Check why striping is slower than writing several files.
-
How about 32 files instead of 16?